Insight.io Tech Stack (2) - Serving and Analysis Pipeline
This next topic I want to cover is the entire backend system including both the serving and source code repository analysis pipeline. Some background context and motivations of this series of posts have already been covered in the previous post Insight.io Tech Stack (1) - RabbitMQ Practices in Insight.io. In short, this stemmed from a recent internal engineering deep dive talk, which I thought might be worthwhile to summarize for future reference.
Framework and Storage Systems
We took Scalability as the first priority from day one (even though this is a bit controversial from today’s point of view.). That’s why we choose Microservices architecture. (Designing and Deploying Microservices from Nginx is a good guidance to start with.)
The RPC framework we use is Twitter Finagle on top of Apache Thrift, an Interface Definition Language (IDL) for both services definition and internal common data structure definition. And Twitter Scrooge to translate Thrift files into Scala source code, since thrift currently does not officially support Scala yet. Also, the main reason why we choose Finagle versus the other is also because of using Scala as our major programming language.
Playframework serves as our web server framework for the sake of Scala as well.
The storage systems we use are also very standard: MongoDB for general data storage, Redis mostly for caching and ElasticSearch for code search indexing.

Analysis Pipeline
As the very first step when a git repository enters our stack, it has to go through an analysis pipeline with primarily 4 steps: Clone/Update, Build, Highlight and Index, depicted as follows:
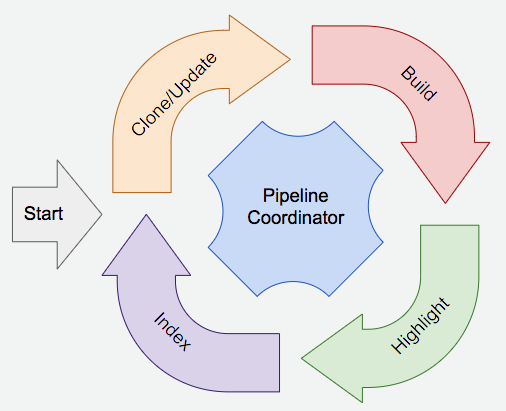
Each of these steps are accomplished by a service and plus the pipeline coordinator service, thus 5 services in total:
- DataService:
DataService is in charge of all git related analysis, including cloning, updating and deleting git repositories by JGit.
- BuildService:
BuildService is the pipeline component which generates the critical source code analysis data, which we called MetaData. The actual source code build job is dedicated to a Jenkins cluster, while the service itself is actually a REST API wrapper of the Jenkins instance.
- PygmentService:
PygmentService serves as the analysis component to generate and store source code syntax highlight data. The reason why store syntax data offline instead of generating them online is because in the code search results, we need to render arbitrary source code segments instead of the entire source code file.
- LiaceService:
LiaceService acts as the source code search indexer for ElasticSearch. To make all the data searchable as a product, we need to index not only the source code itself but also MetaData which denotes the relationships among source files to better rank the search result.
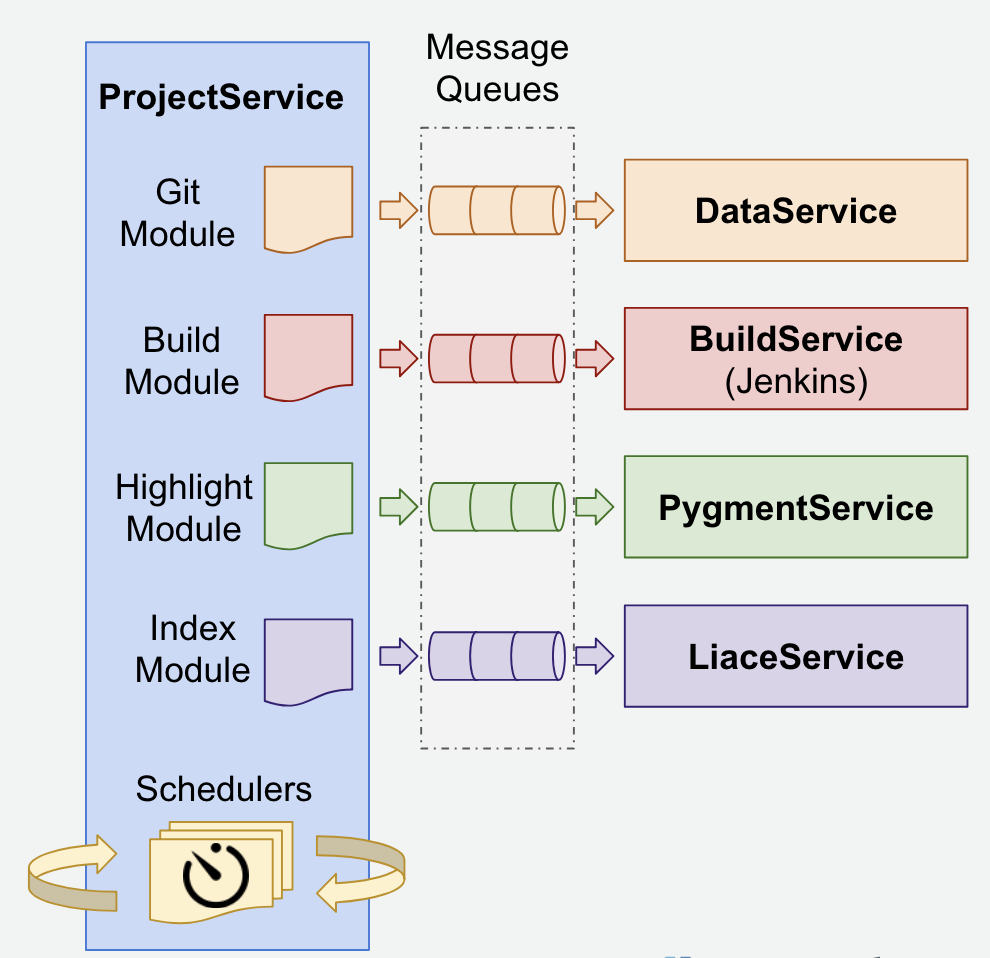
- ProjectService:
ProjectService’s role is the coordinator of the analysis process of each repository. So it dispatches analysis tasks to the corresponding services by posting messages to RabbitMQ. For each service we have, there is a corresponding module for assembling job request message and handle job response message.
Other major components inside ProjectService are schedulers to trigger git repository updates and new build on git repositories periodically to keep all the serving data fresh.
Serving Backend
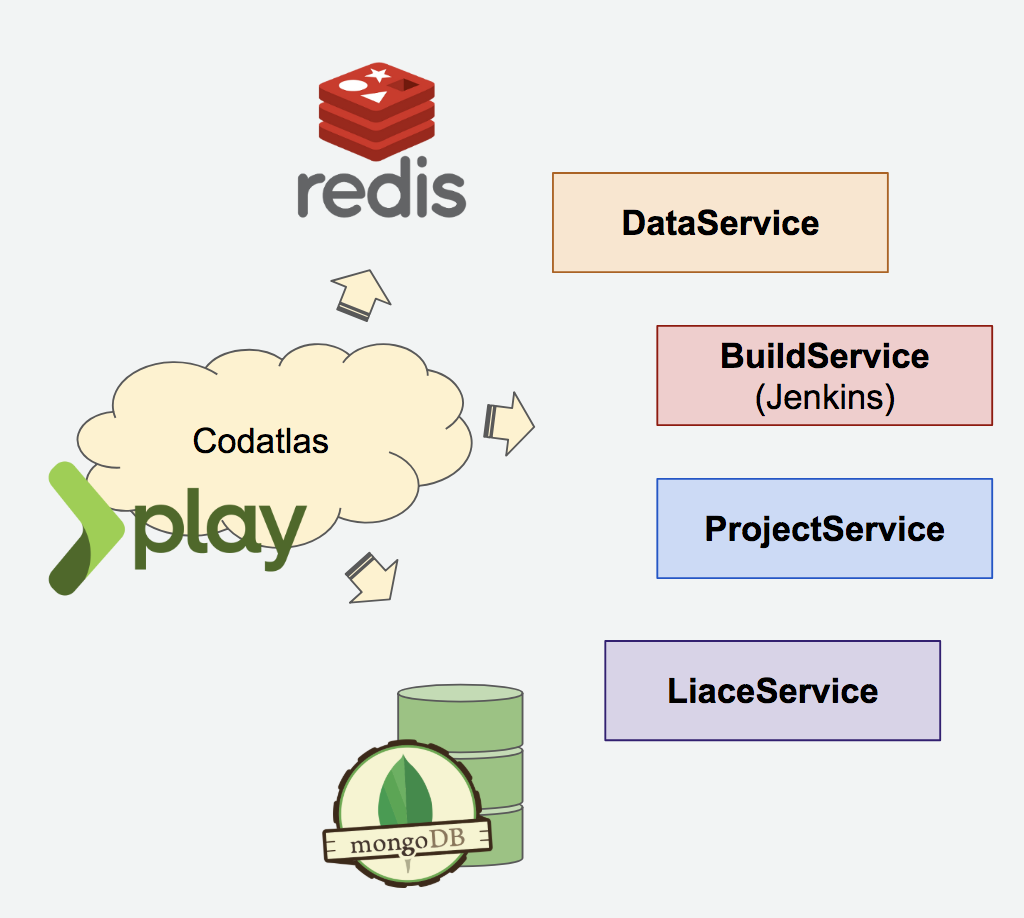
Our web server Codatlas (Code + Atlas was the very first name of our early product) lies at the center of our serving system. It’s built based on Playframework. It serves multiple roles as most of the web servers do:
- REST API & Request Routing:
Codatlas serves as the REST API provider for all of our applications in the front. Some of the APIs can be retrieved directly from MongoDB and some have to be routed to different microservices to fetch the result. Before returning the data to the client, the response is tailored appropriately in Codatlas.
- Result Caching:
Redis cluster is used particularly for REST API response caching and also user login session storage.
- User Management and Data Access Control:
SecureSocial is the middle layer library we use in Playframework for all the user management and data access control. However, with our extensive use, we have hacked the library and almost build another layer on top of it to git our particular use cases. User data is stored in MongoDB, while user session is managed by Redis.
Since we are a developer facing product, we have to integrate with other major git repositories hubs like GitHub, GitLab and BitBucket. Also, for on-premise version, we provide integrations with their enterprise version and also commonly adopted user management system like LDAP, SAML and Kerberos.
More
Again, this is a very high-level walkthrough of the serving and pipeline system. Another 2 topics regarding the system are logging & monitoring and DevOps. I think it’s worth to have a separate post talking about them and please continue to read Insight.io Tech Stack (3) - Infrastructure and DevOps.