Insight.io Tech Stack (4) - All About Frontend
All the previous posts of this Insight.io Tech Stack Series (1. Message Queue, 2. Serving & Pipeline, 3. DevOps & Infra) talked about every aspect of the backend system. Let’s try a different flavor today by diving into our frontend architecture, which is dominated by Javascript.
As elaborated in the first post, the intention is to do some high-level summary of what we have done here at Insight.io in terms of tech stack. I think this not only helps to showcase how we glue open source solutions together into an online service but also as an opportunity to retrospect what we can do better in the future.
Product Overview
Frontend acts as the direct exposure of our services to our end users. Before running into any details of its architecture, it might be helpful to go through our entire product line for the sake of understanding the technical challenges we are dealing with.
Code Browsing/Search
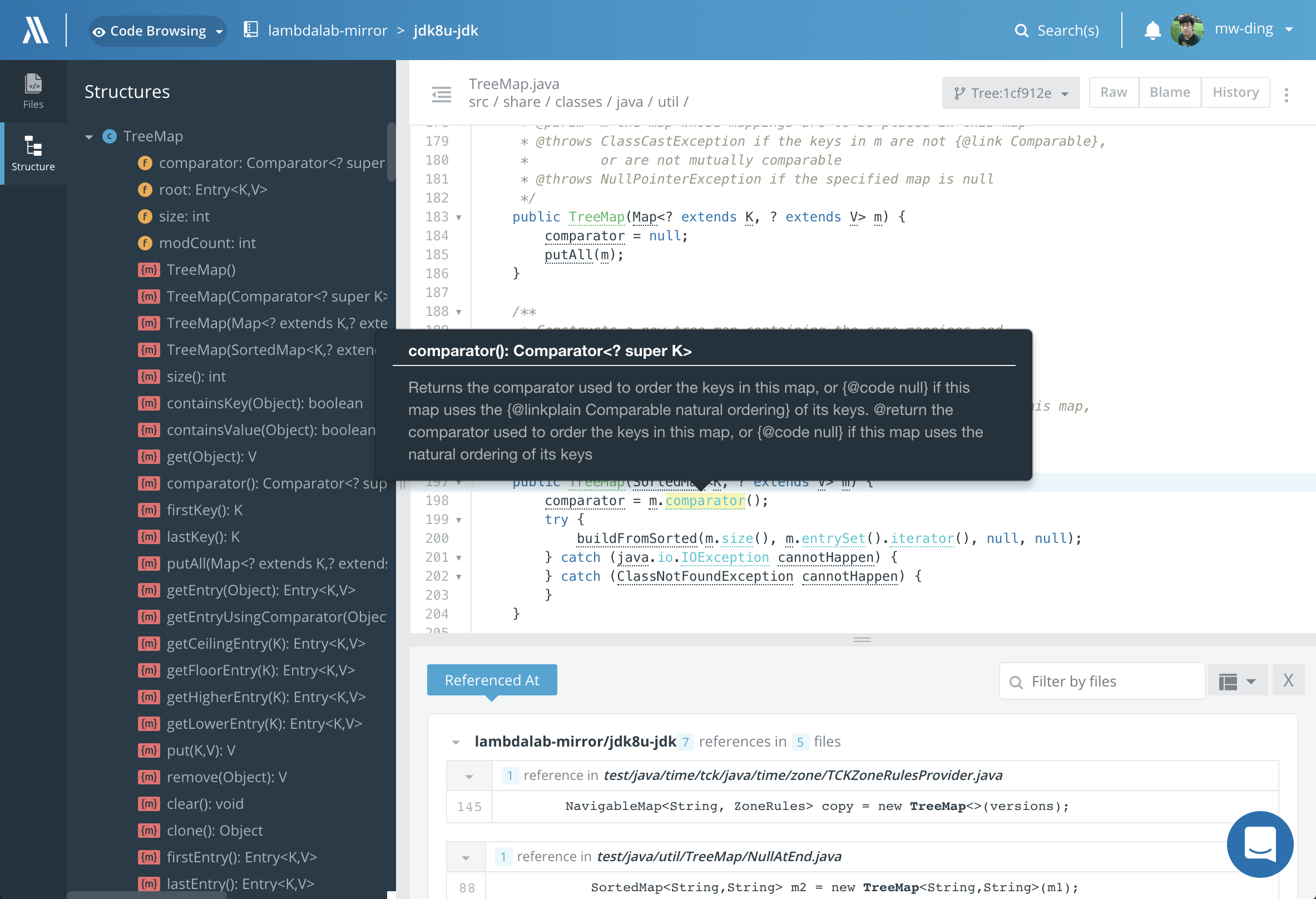
Our first product is an online code browsing and search application. Turbo-charged by our
featured code intelligence engine, our application builds a huge source code reference graph
among all the open source projects included in our system. With that, you can find how an API
function is used in different places with just one click, which helps developers to locate
code online much faster without even opening your heavy weighted IDE. Also, by understanding
the structural relationships of source code files, we rank search results better to help
developers to search code faster than doing a grep.
Code Review
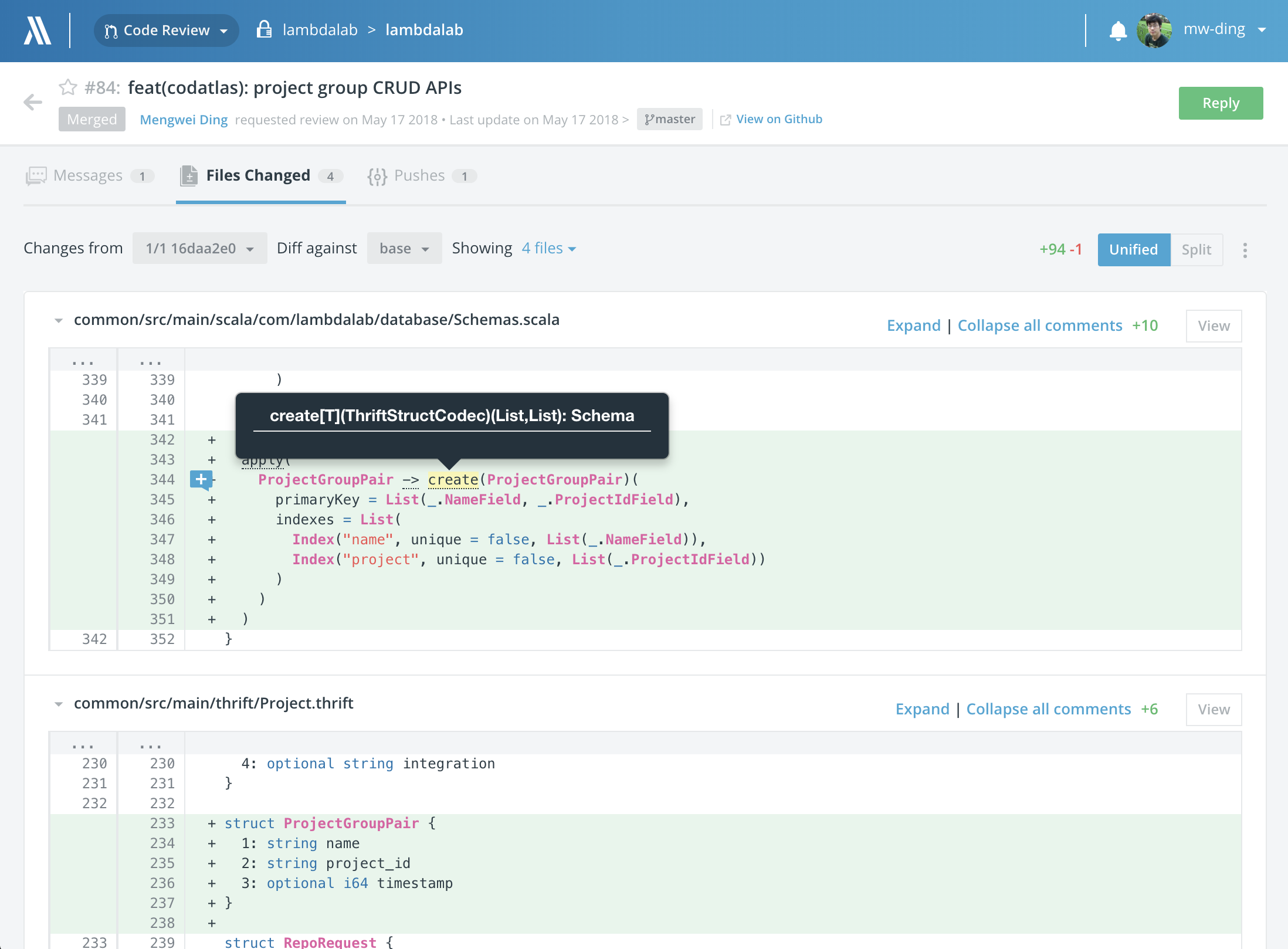
If code browsing and search features do not sound promising enough to you, our code review with code intelligence product will definitely save you a ton of time. As one of the critical steps of software development process, code review takes a big chunk of time in an established tech company, mostly because you have to copy/paste code around and switch between your IDE and code review tools trying to find and understand the entire context of the code changes. With our code intelligence armed, you can locate the exact source code with the full context of the code changes just one click away. This is going to be another efficiency booster to your valuable development process.
Browser Extensions
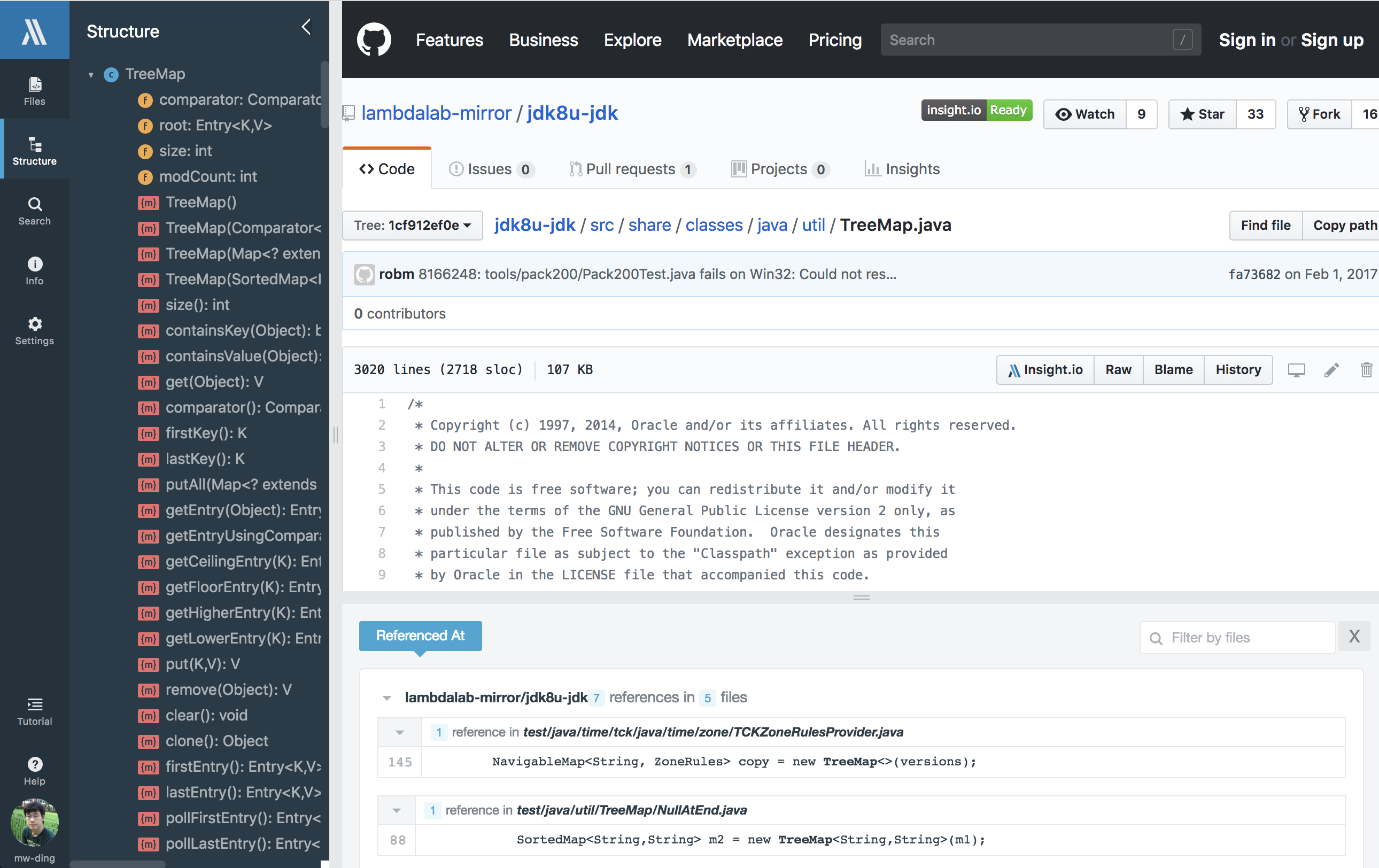
Developers use GitHub (or GitLab/BitBucket) to host and browse their source code in most of the time. Without breaking their conventions, we also built a browser extension product Insight.io for GitHub, bringing our intelligent code browsing experience seamlessly to GitHub itself. It’s available for Chrome, Firefox, and Safari. For our enterprise stack, we also derive similar products for GitLab and BitBucket enterprise versions. This product has been featured as the #3 Product of the Day on ProductHunt.
In short, as a startup which needs to be adaptive to varies kinds of customer feature requests, we have to design and build a frontend architecture elastic enough to serve multiple products running in different environments and flexible to be extended for future new products. And in the meanwhile, it has to be both user and development friendly.
Background
In the very early day when this was still a toy project, without too much frontend development experiences, we built the first prototype of the project with pure jQuery and Bootstrap. There was very little MVC modularization in the code. Data fetching, handling, and view rendering logics were intertwined together in one single source file. As you can imagine, soon as the complexity of the user interaction increases, things went out of control, because we spent too much time on figuring out the actual problem in a massive chunk of code for even a tiny bug fix. It was depressing but also motivating to find the correct solutions like we did for the backend since obviously, we haven’t done things right.
It was the time when React and Flux started to gain a lot of attention and naturally they became the major candidates on our plate. Particularly, Jing’s talk Rethinking Web App Development at Facebook on F8 conference was very inspiring and pinpointed the exact problem in our case. And started from there, we decided to fully embrace React and Flux. Very soon, as we followed the single flow programming pattern of Flux, the structure of our frontend code has never been that clean and organized.
As always, as we keep growing, some drawbacks of the Flux architecture became irritating, like too many redundant codes (e.g. actions), decentralized state management, etc.. We kept diagnosing the essences of these issues and actively looking for best practices from the fast-growing React community. The entire frontend architecture became much more mature and stable along the way after a lot of iterations, as long as we believe in doing the right thing.
Architecture
We use React, period.
Programming Language

Thanks to Babel that we can use Ecmascript 6 (ES6) to build our applications. ES6 provided a lot of modern programming language features (e.g. arrow functions, template literals, destructuring, class, generator, etc.) very close to Scala as of backend development, thus providing a very unified programming experience in the entire stack.
Model
We later use Redux to replace Flux as our core data model management framework. The Three Principles are quite self-explanatory to the reasons we choose it:
- Single source of truth
- State is read-only
- Changes are made with pure functions
To echo the second principle, we adopt Immutable.js to protect the read-only global state.
![]()
Redux-Saga is the framework we use for managing remote asynchronous data exchanging. Its innovative way of using generator in ES6 make asynchronous flows look like standard synchronous code, which hugely improves the beauty of the code. Thus it stands out from other candidates like Redux Thunk.
For some real-time sensitive data exchanges use cases, we use WebSockets to adopt data pushing instead of just pulling.
Controller

For component routing control, React Router is the default choice for React based applications. To make sure the routing params can be accessed from Redux, we did some plumbing work ourselves to make it real, since it’s a React library not designed particularly for Redux.
View
One of the standards in React community nowadays is importing CSS files into Javascript as modules, so that frontend source codes can be managed by a single module system. There are a couple of such libraries can do so. We use PostCSS and its Webpack loader to achieve this.
For other static files, like fonts, images, we also use Webpack loaders so that they can be accessed directly from the Javascript source code.
Performance Tuning
In most of the time, React performs well in terms of rendering latency. Occasionally, we encountered performance issues with React and that’s when performance tuning is unavoidable.
One example is rendering the file diff view in our code review product. There could be a huge amount of very tiny React components in a single file diff view, particularly when the source file is large, because for each token (e.g. functions, variables, keywords, etc.) is a single component, and it could also be wrapped by syntax highlight, hovering highlighting and code intelligence decoration components.
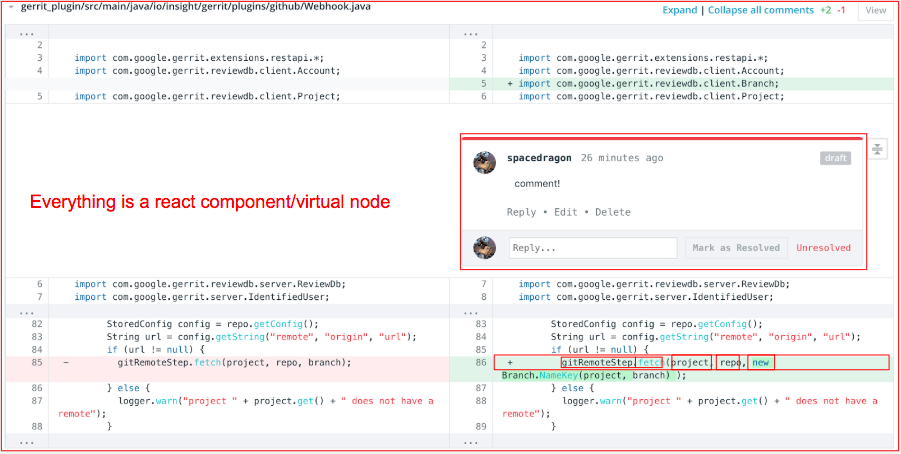
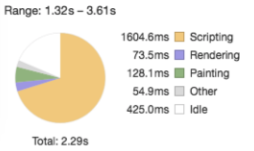
This big amount of components could result in a very large chunk of Scripting latency in the browser. This deteriorates the user experience a lot, particularly when there are a lot of file diff views in a code review (which is very common). User’s browser would freeze for a very long time and sometimes even crashes.
To solve this issue, we move the file diff view rendering from client/browser side to server side as APIs. The entire file diff view is rendered in the server and returned as pure HTML. Now React does not need to deal with any DOM computation which reduces a huge amount of Scripting time. This server-side rendering solution immediately solves the user experience issue that the browser won’t freeze any more.
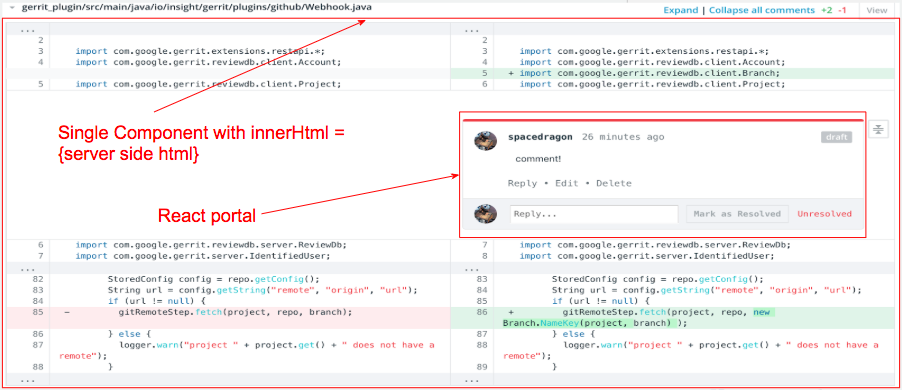
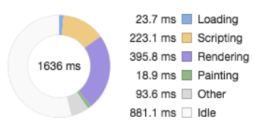
One downside of this solution is that the file diff views HTML won’t be included into React’s virtual DOM hierarchy and cannot be managed by React. But thanks to React Portals introduced since React Fiber (16), we can still render and manipulate children components in this pure HTML DOM node.
Monitoring & Tracking
We use Google Analytics to do some high level user behavior and traffic tracking, use Inspectlet to sample user’s real behavior playbacks. What we rely on the most is actually custom event tracking on Mixpanel, including but not limited to:
- Event Segmentations
![]()
- Funnel Analysis
![]()
- Retention Analysis
![]()
To redirect all the custom events into Mixpanel, we implemented a light weighted React wrapper as a framework to intercept user actions and transform into events. By default, it has a Mixpanel adapter which commits events to Mixpanel. For enterprise version, we can plugin a Logstash adapter to redirect events to Elasticsearch.
Dev Tools
We use Yarn to manage our javascript dependencies and define build tasks. To follow our own convention of using Gradle to manage build tasks, we use gradle-node-plugin to trigger Yarn tasks with Gradle.

For bundling and packaging Javascript, CSS, image and font files, we heavily rely on Webpack. With various resource loaders, we decompose our applications into a lot of separate modules. This helps to relieve the pain to manage different frontend resources. Also, its dev server facilitates our frontend development process by its featured live reloading, so that your local changes can be applied instantaneously without manually reload your frontend application.
For React application, we heavily rely on React Developer Tools and Redux Dev Tools Chrome extensions. Particularly, the ability of Redux Dev Tools plugin to jump to arbitrary application helps the debugging a lot.
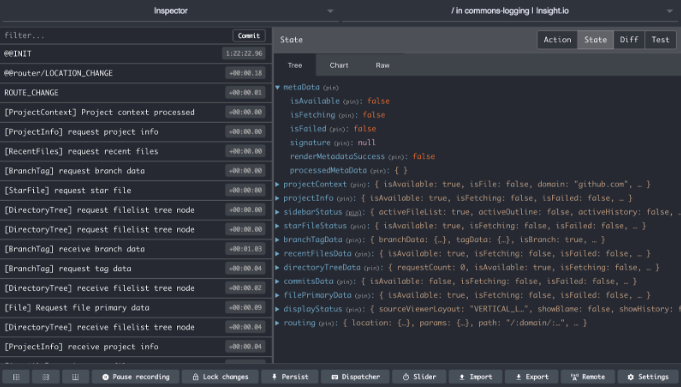
In a lot of cases when doing purely frontend development, we only touch Javascript source codes. It would be burdensome to start then entire backend stack to verify some functionalities and it would be helpful just reusing some existing stacks. In our case, we have a long-running test and staging stack on our K8s cluster, particularly for regression tests. Thus, I built a quick Chrome extension, which, when enabled, always redirects the actual Javascript and CSS bundle asset files on test and staging stack to our local webpack dev server, which contains the latest changes on the local dev machine.
The implementation is quite straight-forward, just leveraging the chrome API
(chrome.webRequest.onBeforeRequest.addListener) to intercept the web requests to fetch all
the javascript and css files before it has been sent and simply return a redirection result to
the corresponding urls on the local webpack dev server.
chrome.webRequest.onBeforeRequest.addListener(
(info) => {
const assetRegex = /https?:\/\/[^/]+\/assets\/dist\/codatlas\/[0-9a-f]*-(.*)\.(css|js)/;
const m = info.url.match(assetRegex);
if (interceptorOn && !!m) {
const name = m[1];
const ext = m[2];
const destUrl = `http://localhost:9090/assets/dist/codatlas/${name}.${ext}`;
console.log(`Redirect ${info.url} to ${destUrl}`);
return {
redirectUrl: destUrl
};
}
return null;
},
// filters
{
urls: [
'http://test.insight.io/assets/dist/*',
'https://staging.insight.io/assets/dist/*'
],
types: ['script']
},
// Handle the call back synchronously.
['blocking']
);
Conclusion and The Future
We are trying our best to apply the state-of-art frontend best practices, frameworks and libraries into our frontend architecture to reach the best user and development experience. However, the frontend technologies evolve so fast that we don’t really have that much bandwidth to achieve this goal 100%. A couple of examples would be that we have always wanted to do are switching to Typescript to better integrate with Thrift data structure definitions, using GraphQL to improve our data model management, etc..
From a positive point of view, it’s always good to retrospect and identify some aspects that we can do better. That is when growth and learning are happening. In the future, when we have the chances to do it again, we can definitely do it in a better way.